이번 글에서는 실제 JPA를 사용해서 테이블과 매핑하는 방법에 대해서 적어볼게요..
엔티티 매핑 종류
- 객체와 테이블 매핑 : @Entity, @Table
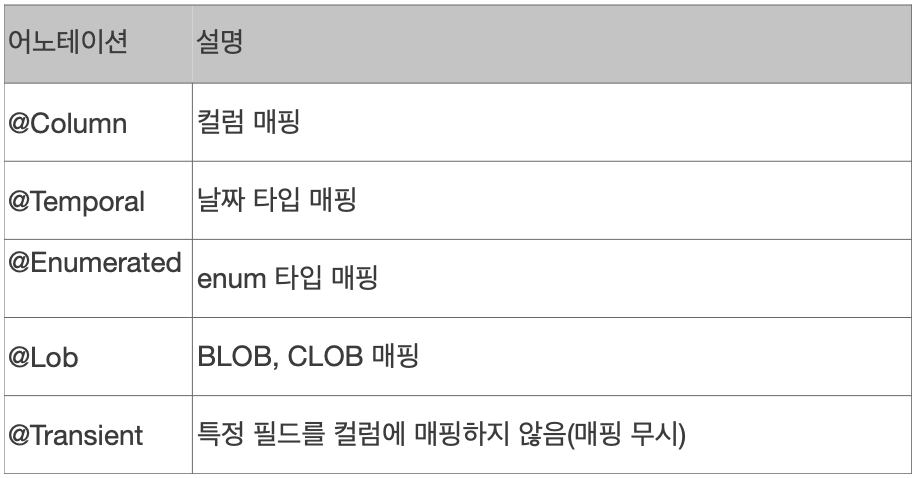
- 필드와 컬럼 매핑 : @Column
- 기본 키 매핑 : @Id
- 연관관계 매핑 : @ManyToOne, @JoinColumn
@Entity
- @Entity가 붙은 클래스는 JPA가 관리, 엔티티라 한다.
- JPA를 사용해서 테이블과 매핑할 클래스는 @Entity 필수
+ 속성 : name
- JPA에서 사용할 엔티티 이름을 지정
- 기본값 : 클래스 이름을 그대로 사용(예 : Member)
- 같은 클래스 이름이 없으면 가급적 기본값을 사용한다.
@Table
- @Table은 엔티티와 매핑할 테이블 지정
+ 속성 : name - 매핑할 테이블 이름
+ 속성 : catalog - 데이터베이스 catalog 매핑
+ uniqueConstraints(DDL) -DDL 생성 시에 유니크 제약 조건 생성
주의사항
- 기본 생성자 필수(파라미터가 없는 Public 또는 Protected 생성자)
- final 클래스, enum, interface, inner 클래스 사용X
- 저장할 필드에 final 사용 X
데이터베이스 스키마 자동 생성
- DDL을 애플리케이션 실행 시점에 자동 생성
- 테이블 중심 -> 객체 중심
- 데이터베이스 방언을 활용해서 데이터베이스에 맞는 적절한 DDL 생성
- 이렇게 생성된 DDL은 개발 장비에서만 사용
- 생성된 DDL은 운영서버에서는 사용하지 않거나, 적절히 다듬은 후 사용
hibernate.hbm2ddl.auto 옵션 사용
- create : 기존 테이블 삭제 후 다시 생성(DROP + CREATE)
- create-drop : create와 같으나 종료시점에 테이블 DROP
- update : 변경분만 반영(운영DB에는 사용하면 안됨) / 지우는것은 안됨
- validate : 엔티티와 테이블이 정상 매핑되었는지만 확인
- none : 사용하지 않음
데이터 베이스 스키마 자동 생성시 주의할점!!
- 운영 장비에는 절대로 create, create-drop, update를 사용하면 안된다.
- 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영서버는 validate 또는 none 사용
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- 데이터베이스 스키마 자동 생성 속성으로 운영서버에서는 사용하지 말 것! -->
<!--
create 기존테이블 삭제 후 다시 생성
create-drop create와 같으나 종료시점에 다시 drop (테스트 할 경우에 보통 사용)
update 변경분만 반영(운영DB에는 사용하면 안됨)
validate 엔티티와 테이블이 정상 매핑되었는지만 확인
none 사용하지 않음
운영 장비에는 절대 create, create-drop, update를 사용하면 안된다.
개발 초기 단계에는 create 또는 update
테스트 서버는 update 또는 validate
스테이징과 운영 서버는 validate 또는 none
-->필드와 컬럼 매핑
- 대게 컬럼 매핑하는 예시는 아래와 같으며 어떻게 매핑할건지는 설정해주는 거에 따라 다르다.
@Entity
public class Member {
@Id // 기본키 매핑
private Long id;
@Column(name = "name") // 컬럼명이 username이지만 실제 디비에는 name과 연결하겠다라는 뜻
private String username;
private Integer age;
@Enumerated(EnumType.STRING)
// Enum 타입일 경우 사용하는데 ORDINAL은 사용하지 말자
// ORDINAL은 순서를 디비에 저장하기때문에 예외사항이 발생할 수 있다.
// Enum 타입은 그냥 아무생각말고 STRING을 사용하자!!!
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP) // 날짜형 타입
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
// 자바8 이후로는 하이버네이트에서는 LocalDate, LocalDateTime을 구분을 알아서 해준다. 그냥 쓰자
// 옛날 버전인경우는 위와같이 @Temporal로 사용한다.
private LocalDate testLocalDate;
private LocalDateTime testLocalDateTime;
@Lob // blob, clob 등의 데이터를 선언
private String description;
}
@Column 타입의 속성

기본 키 매핑 방법
- 직접 할당 : @Id만 사용
- 자동 생성(@GeneratedValue)
- IDENTITY : 데이터베이스에 위임, MYSQL
- SEQUENCE : 데이터베이스 시퀀스 오브젝트 사용, ORACLE → @SequenceGenerator 필요
- TABLE : 키 생성용 테이블 사용, 모든 DB에서 사용 → @TableGenerator 필요
- AUTO : 방언에 따라 자동 지정, 기본 값
IDENTITY 전략 - 특징
- 기본 키 생성을 데이터베이스에 위임
- 주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용
- JPA는 보통 트랜잭션 커밋 시점에 INSERT SQL 실행
- AUTO_INCREMENT는 데이터베이스에 INSERT SQL을 실행한 이후에 ID 값을 알 수 있음
- IDENTITY 전략은 em.persist() 시점에 즉시 INSERT SQL 실행 하고 DB에서 식별자를 조회
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
// IDENTITY로 하게되면 디비에 값이 들어가봐야 PK가 뭔지 알기떄문에 제약이 있음
private Long id;try{
Member member = new Member();
member.setUsername("C");
System.out.println("===========");
em.persist(member);
System.out.println("member.id = " + member.getId());
System.out.println("===========");
//원래는 커밋하는 시점에 쿼리가 날라가야하는데 그러게되면 PK값을 알 수 없다.
//IDENTITY 일 경우에만 예외적으로 em.persist 함과 동시에 디비로 값이 날라가서 ID(PK)값을 알 수 있게됨
tx.commit();
SEQUENCE 전략 - 특징
- 데이터베이스 시퀀스는 유일한 값을 순서대로 생성하는 특별한 데이터베이스 오브젝트(오라클 시퀀스)
- 오라클, PostgreSQL, DB2, H2 데이터베이스에서 사용
try{
// 1. JPA는 우선 member 객체를 만든다.
Member member = new Member();
member.setUsername("C");
System.out.println("===========");
// 2. em.persist 할때 영속성 컨텍스트에 넣어야하는데 그럴려면 PK가 필요함 ...
// 그렇게되면 먼저 시퀀스를 가져와야한다!
// 5. 값을 가져와서 저장한 후에 영속성 컨텍스트에 저장한다.
// 6. 디비에 아직 INSERT 쿼리는 안날라가고 (필요에 따라 버퍼링을 해야하니) 영속성 컨텍스트에 쌓아둔다.
em.persist(member);
System.out.println("member.id = " + member.getId());
System.out.println("===========");
// 7. 커밋 하는 시점에 쿼리가 디비로 날라간다. (즉 SEQUENCE 방식은 버퍼링이 가능하다라는 뜻)
tx.commit();@Entity
// 3. JPA는 어? 너 시퀀스 전략이네! 란걸 확인하고 값을 먼저 가져올게 하고 동작하여 값을 가져오게된다.
@SequenceGenerator(
name = “MEMBER_SEQ_GENERATOR",
sequenceName = “MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "MEMBER_SEQ_GENERATOR")
// 4. 시퀀스 전략인걸 확인하고 나서 JPA는 가져온 값을 member에 id에 값을 넣어준다.
private Long id;
@SequenceGenerator 전략
- initialValue 옵션과 allocationSize 옵션을 통해서 성능을 최적화한다라는 점만 기억!

TABLE 전략
- 키 생성 전용 테이블을 하나 만들어서 데이터베이스 시퀀스를 흉내내는 전략
- 운영에서는 아무래도 사용하기 꺼려진다. 성능이 안좋음

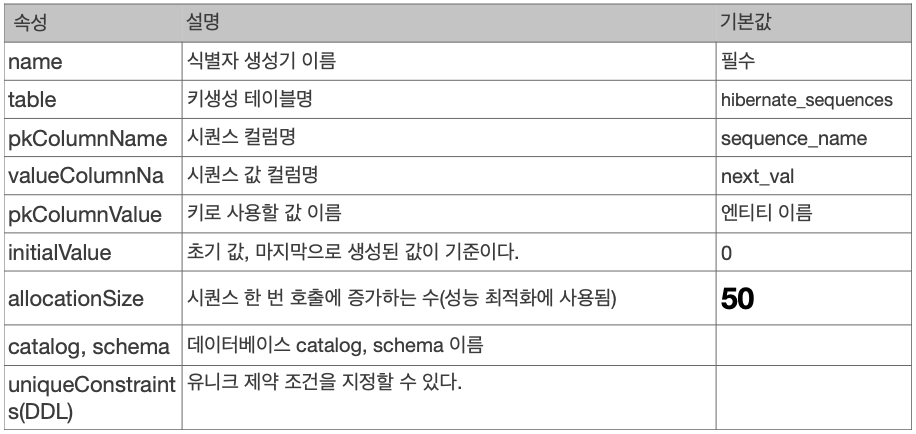
권장하는 식별자 전략
- 기본키 제약 조건 : null 아님, 유일, 변하면 안된다.
- 미래까지 이 조건을 만족하는 자연키는 찾기 어렵다. 대리키(대체키)를 사용하자
- 예를 들어 주민등록번호도 기본 키로 적절하지 않다.
- 권장 : Long형 + 대체키 + 키 생성전략 사용
'Dev > JPA' 카테고리의 다른 글
| 다양한 연관관계 매핑 (0) | 2020.07.28 |
|---|---|
| 연관관계 매핑 기초 (0) | 2020.07.15 |
| JPA내부 구조(영속성 관리) (0) | 2020.07.06 |
| JPA의 등장 (0) | 2020.06.30 |
| SQL중심개발의 문제점 (0) | 2020.06.30 |


